(ICML 21) Scaling Up Visual and Vision-Language Representation Learning With Noisy Text Supervision
0. Abstract
Conceptual Captions, MSCOCO 그리고 CLIP을 학습하는 데 사용한 데이터셋들은 non-trival data collection과 cleaning process를 가지고 있습니다. 이러한 값비싼 데이터셋 Curation 과정은 데이터셋 크기를 제한하고 학습된 모델의 크기가 커지는 것을 방해합니다. 본 논문에서 제안하는 Dual-encoder 구조는 contrastive loss로 정렬된 visual과 language 사이의 representation을 배웁니다. noise한 텍스트 데이터의 corpus를 증가시키는 간단한 학습 전략은 복잡한 텍스트, 텍스트+이미지 쿼리의 cross-modality search를 가능하게 합니다.
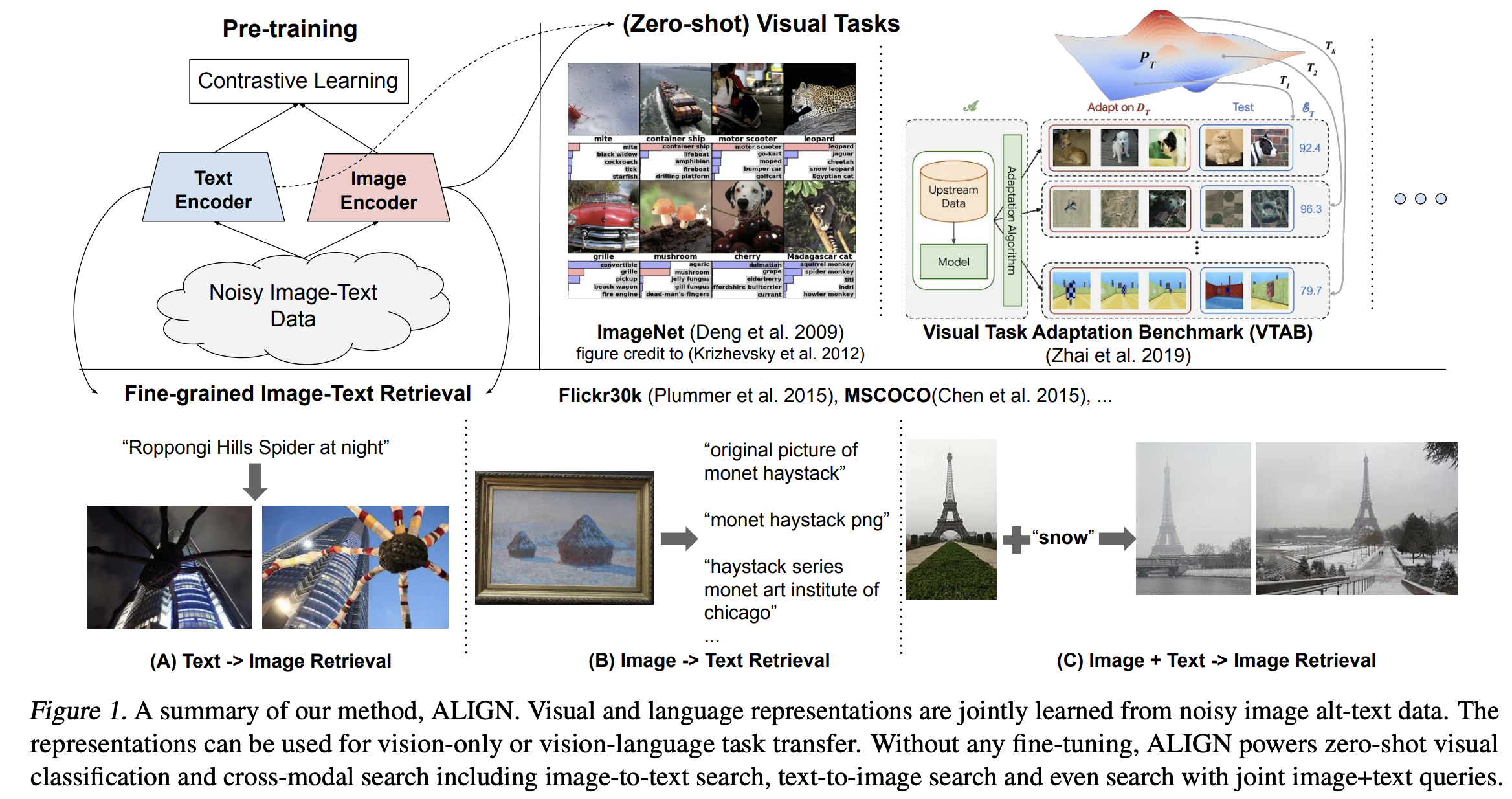
1. Introduction
Why do we need noisy data?
Conceptual Captions, Visual Genome Dense Captions 그리고 ImageBERT는 human annotation, semantic parsing, cleaning and balancing 작업이 들어가기 때문에 데이터셋을 만드는데 많은 노력이 들어갑니다. 데이터 셋 역시 10M 예시 정도 밖에 만들 수 없는 단점이 있습니다. 이는 NLP pre-training에 사용되는 데이터셋의 개수에 비하면 매우 작습니다.
Noisy image alt-text pairs
따라서 vision-language representation learning에 필요한 데이터 개수를 증가시키기 위하여, one billion noisy image alt-text pairs를 leverage, 사용합니다. 다양한 데이터 클리닝 전략을 사용하는 것 대신에 Conceptual Captions Dataset에 오직 frequency-based filtering 전략만을 사용합니다. 이러한 exascale dataset으로 사전 학습한 모델은 다양한 task에서 강력한 성능을 가집니다.

Contribution
Dual-encoder 구조로 visual과 language representation이 Shared latent embedding space를 가지도록 합니다. ALIGN: A Large-scale ImaGe and Noisy-embedding 은 Flicker30K과 MSCOCO에서 zero-shot 그리고 fine-tuned R@1 metrics에서 SOTA 성능을 달성합니다. 또한 이미지넷에서 88.64% top-1 acc 성능을 달성합니다.
2. Related Work
CLIP과 매우 접근이 유사하지만 다른 점은 training data입니다. CLIP은 English Wikipedia로부터 데이터셋을 수집하지만 ALIGN은 raw alt-text data로부터 나온 거의 모든 image-text pair 데이터셋을 사용합니다. 이는 natural한 distribution을 따를 수 있는 장점이 있습니다.
3. A Large-Scale Noisy Image-Text Dataset
데이터 크기를 증가하는 것이 본 논문이 주 목적이므로 cleaning step의 대부분을 완화하는 전략을 사용합니다.
Image-based filtering
가로, 세로 중 더 짧은 길이가 200보다 큰 이미지를 사용합니다. 또한 aspect가 3보다 작은 이미지를 사용합니다.
Text-based filtering
1920X1080, alt_img, cristina와 같이 10장의 이미지보다 더 많이 공유된 alt-texts를 제외합니다. 3 보다 작은 그리고 20보다 큰 unigram도 삭제합니다.
4. Pre-training and Task Transfer
4.1 Pre-training on Noisy Image-Text Pairs
ALIGN은 dual-encoder 구조를 사용합니다. 이미지 인코더로는 Efficient with global pooling (without training the 1x1 conv layer in the classification head), 텍스트 인코더로는 BERT with [CLS] token을 사용합니다. 이미지 인코더와 출력 차원을 같게 하기 위해 BERT에 Fully connected layer를 추가로 쌓습니다.
최소화하고자 하는 손실 함수는 image-to-text, text-to-image 2가지입니다.
image-to-text:
\[L_{i2t}=-{1 \over N} \sum_i^N{\log}{\exp({x_i^{\top}y_i/\sigma})\over{\sum_{j=1}^N\exp({x_i^{\top}y_j/\sigma}})}\]text-to-image:
\[L_{t2i}=-{1 \over N} \sum_i^N{\log}{\exp({y_i^{\top}x_i/\sigma})\over{\sum_{j=1}^N\exp({y_i^{\top}x_j/\sigma}})}\]$x_i$와 $y_j$는 i번째 pair의 이미지와 j번째 pair의 텍스트 normalized embedding 입니다. $N$은 배치의 크기이고, $\sigma$는 temperature scale을 뜻합니다. 또한 모든 컴퓨팅 코어에 들어있는 임베딩을 concatenate하여 더 큰 batch를 만듭니다. temparature scale은 manually 찾는 것 대신에 다른 파라미터들과 함께 학습시킵니다.
4.2 Transferring to Imgae-Text Matching & Retrieval
Flicker30K와 MSCOCO를 벤치마크로 사용합니다. 또한 MSCOCO의 연장한 버전인 Crisscrossed Captions (CxC)를 평가하는데 사용합니다.
4.3 Transferring to Visual Classification
ImageNet에 대하여 top classification layer만 학습한 것과 fully-fine-tuned한 것에 대하여 정확도를 측정합니다.
5. Experiments and Results
이미지 인코더는 EfficentNet-L2 그리고 텍스트 인코더는 BERT-Large를 사용합니다. 이미지 인코더는 289X289 해상도를 사용합니다. 346X346으로 resize 후 RandomCrop을 학습과정에서 사용하고 평가 때는 289로 CenterCrop합니다. 입력 텍스트는 최대 64 토큰을 사용하고 20 unigram을 넘지 않습니다. Softmax temparature는 1.0으로 초기화합니다. 그리고 0.1을 label smoothing parameter로 사용합니다. LAMB optimizer를 decay ratio 1e-5를 사용합니다. Learning rate는 10k steps동안 zero에서 1e-3으로 선형으로 warm up합니다. 1024 Cloud TPUv3코어를 사용하고 각 코어마다 16 positive paris가 있습니다. 총 batch size는 16384입니다.
5.1 Image-Text Matching & Retrieval
Fine-tuning 할 때는 배치사이즈를 16384에서 2048로 낮춥니다. Table1을 보면 ALIGN은 Flicker30K와 MSCOCO 벤치마크에서 모든 metric으로부터 SOTA 성능을 달성합니다. Table1은 Flicker30과 MSCOCO 벤치마크에서 SOTA 성능을 달성함을 보여줍니다. zero-shot setting에서 ALIGN은 retrieval task에서 CLIP보다 7% 올랐고, Fine-tuning setting에서 ALIGN은 ImageBERT와 UNITER를 이깁니다.
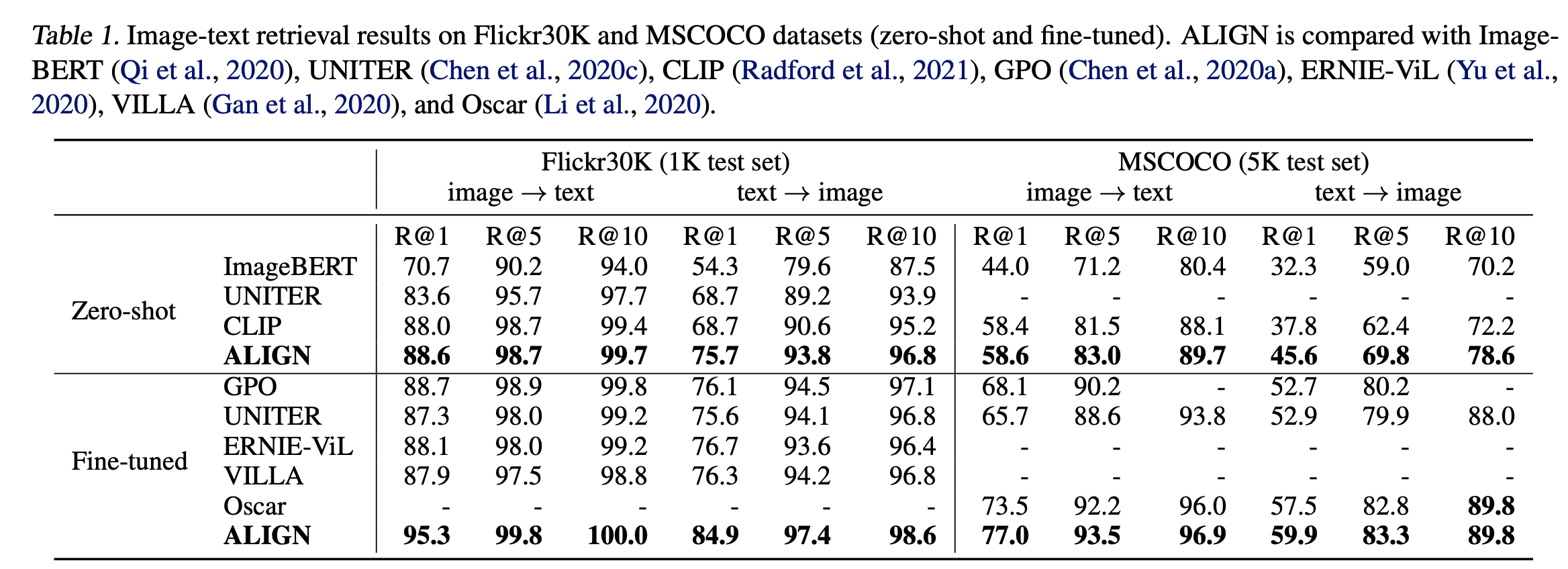
Table2는 CxC retrieval task에서의 비교 결과입니다. 여기서 주목할만한 점은 image와 text 사이의 retrieval 성능은 올랐지만 image와 image, text와 text 등 inter-modal task에서는 성능이 크게 오르지 않았습니다.
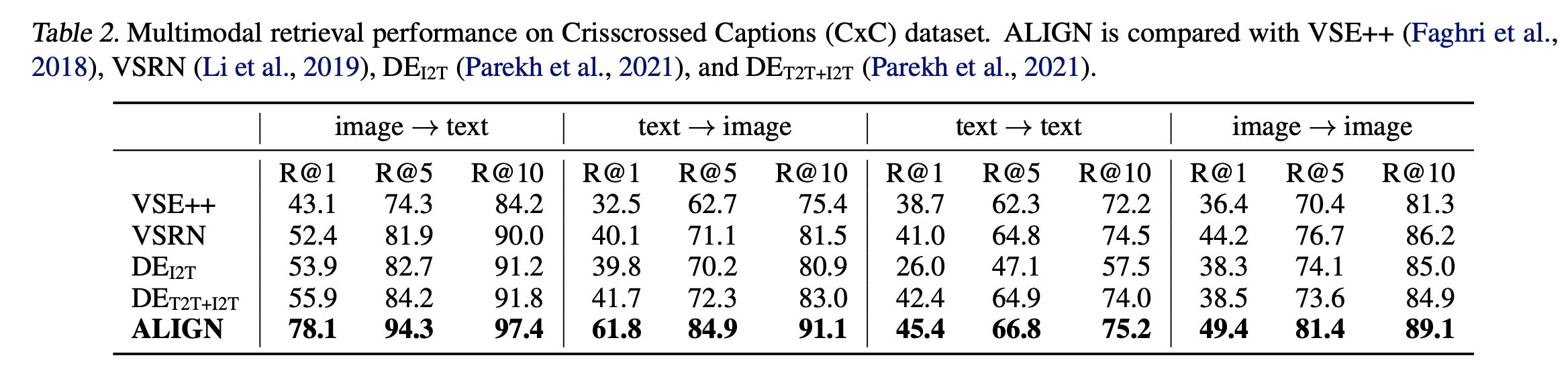
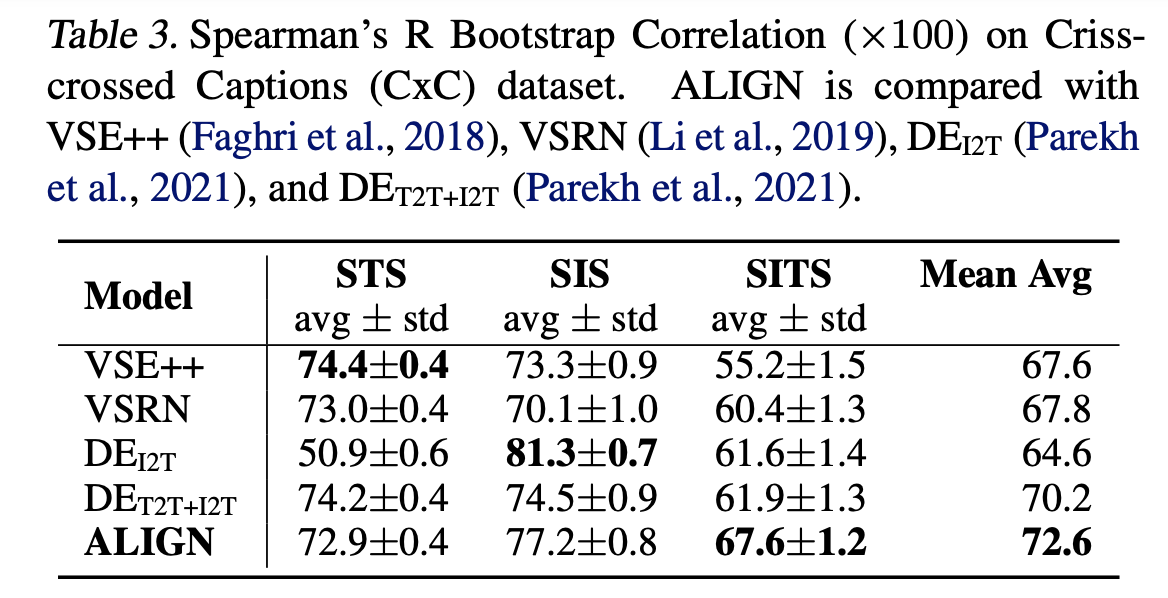
Table3는 SITS task에 대한 ALIGN의 성능을 보여줍니다. training objective가 ALIGN은 cross-modal matching에 맞추고, VSE++은 intra-modal matching하는 것으로 다르기 때문에 VSE++의 기존 모델이 더 좋게 나왔다고 설명합니다.
5.2 Zero-shot Visual classification
CLIP과 마찬가지로 ALIGN은 다른 이미지 분포에서 greate robustness를 가집니다. 공정한 비교를 위해 CLIP과 같은 prompt ensembling 기법을 적용합니다. “A photo of a {classname}” L2 normalization의 모든 템플릿의 평균을 구합니다. 그 결과 CLIP과 마찬가지로 classification task에서 높은 robustness를 가집니다.
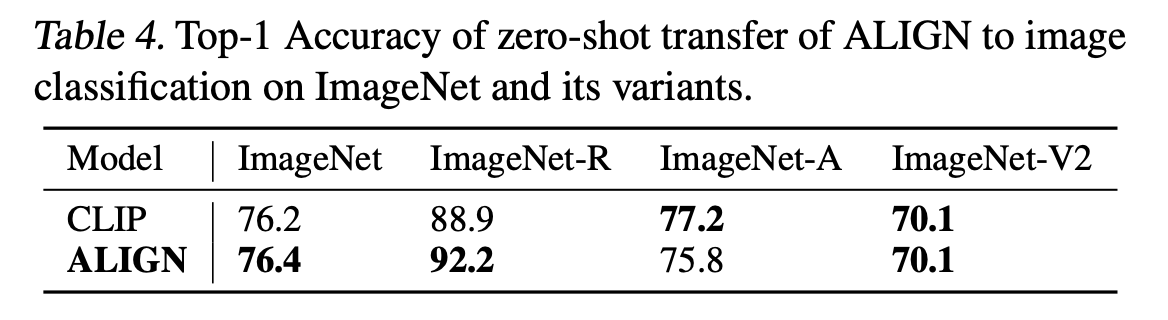
5.3 Visual Classification w/ Image Encoder Only
Table5는 ALIGN과 ImageNet Benchmark에서 성능을 비교한 표입니다. frozen features로 ALIGN은 CLIP보다 약간 더 높은 성능을 보입니다. Fine-tuning 했을 때는 EfficientNet-L2의 Meta-Pseudo Labels를 제외하고 가장 높은 성능을 보입니다.

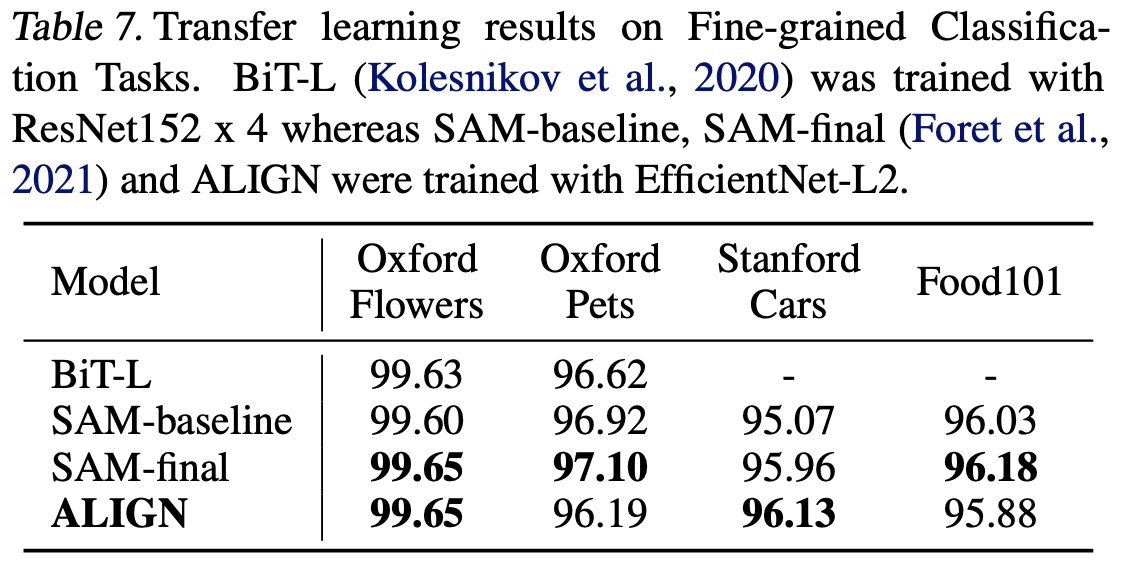
Table6는 VTAB의 19가지 task에서 ALIGN과 Bit-L 사이의 평균 정확도를 비교한 것입니다. 비슷한 hyper-parameter selection method를 적용할 때 ALIGN이 더 우수함을 보여줍니다. data augmentation과 optimizer를 ImageNet fine-tuning 전략을 사용합니다. Classification head를 학습하고 모든 layer를 fine-tune합니다. 이 때 batch norm statistics는 frozen됩니다. train/eval resolution은 289/360입니다. 배치 사이즈는 256, weight decay는 1e-5입니다. 초기 학습률은 1e-2, 1e-3이고, 20k steps마다 cosine learning decay를 적용합니다.
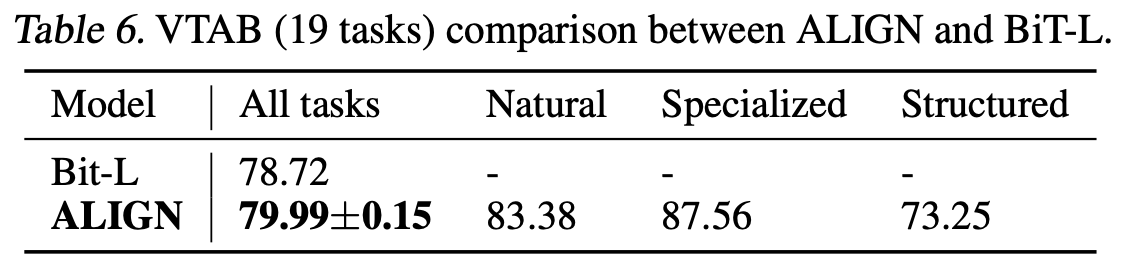
Table7은 Transfer learning을 적용한 결과입니다.
6. Ablation Study
MSCOCO의 zero-shot retrieval과 ImageNet KNN task Ablation study를 진행합니다.
6.1 Model Architectures
Figure 3는 다양한 조합의 텍스트 인코더와 이미지 백본에 대한 zero-shot retrieval 성능을 나타낸 것입니다.
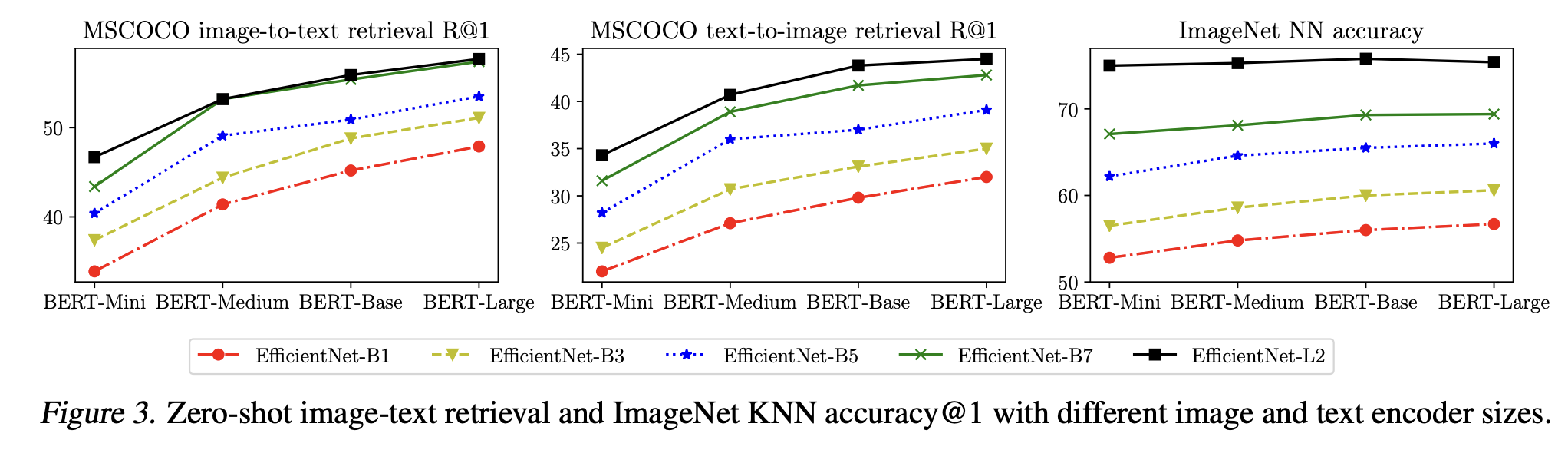
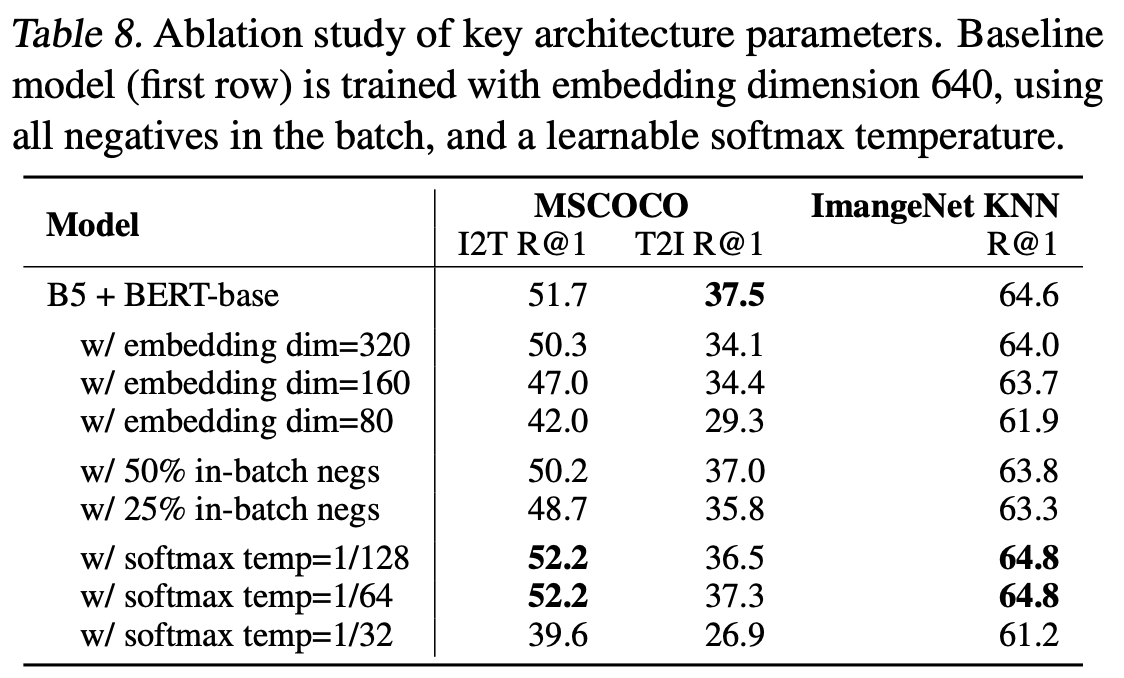
Table 8은 더 높은 임베딩 차원이 모델의 성능을 높임을 보여줍니다.
6.2 Pre-training Datasets
ALIGN의 Full data, 10% randomly sampled ALIGN training data, and Conceptual Captions을 사용합니다. 모든 모델은 scratch부터 학습이 됩니다. Table 9는 scaling up 하는 것이 모델 Performance에 결정적임을 보여줍니다.
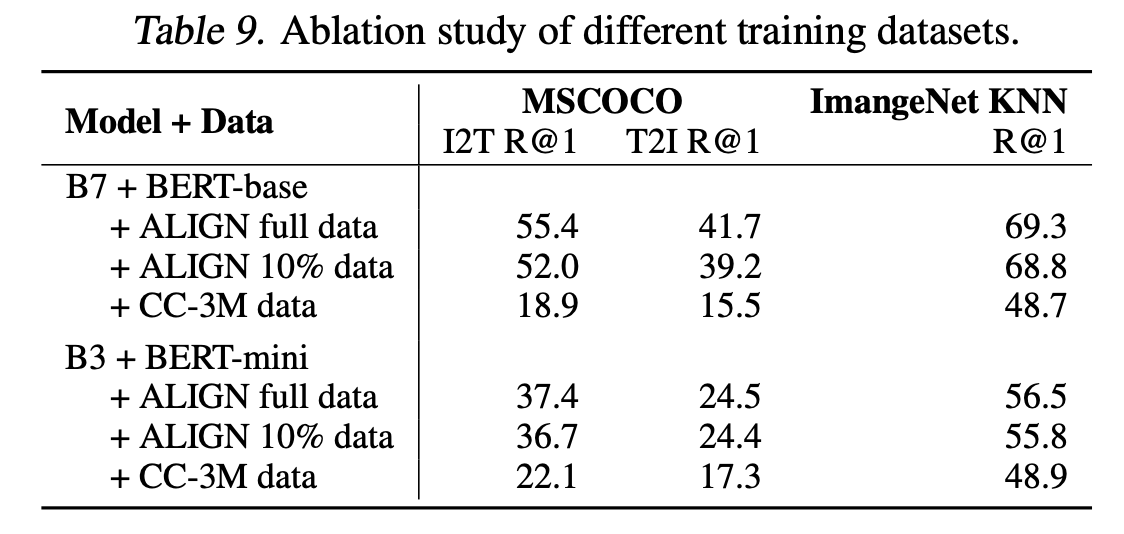
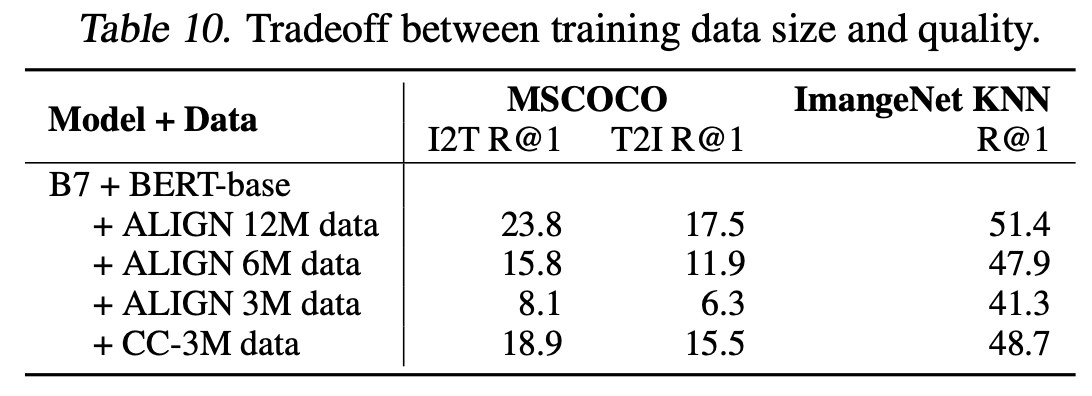
Table 10은 CC-3M 같은 크기의 ALIGN data를 넣을 때 성능이 좋지 않음을 보여줍니다.
7. Analysis of Learned Embeddings
학습 데이터에 없는 text query로 정밀한 검색이 가능하다는 것을 보여줍니다.
Figure 4는 top 1 text-to-image retrieval results를 보여줍니다. training data에 없는 query이기에 더욱 의미가 있습니다.

Figure5는 image+text query에 따른 검색 결과입니다. 임베딩을 더하거나 빼면 의미있는 검색 결과를 얻을 수 있습니다.

8. Multilinugal ALIGN Model
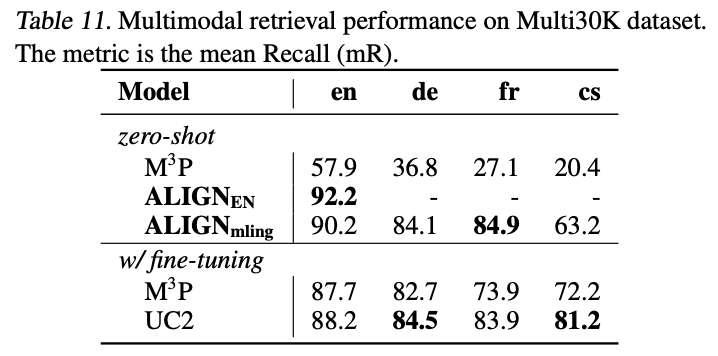
Table 11은 Multi30K에 따른 결과를 나타낸 것입니다. 모든 언어들에 대하여 잘 outperform하는 것을 볼 수 있습니다.
9. Conclusion
A large-scale noisy image-text data to scale up visual and vision-language representation learning.