
Presentation Video
Abstract
Current multi-view 3D object detection methods often fail to detect objects in the overlap region properly, and the networks' understanding of the scene is often limited to that of a monocular detection network. Moreover, objects in the overlap region are often largely occluded or suffer from deformation due to camera distortion, causing a domain shift. To mitigate this issue, we propose using the following two main modules: (1) Stereo Disparity Estimation for Weak Depth Supervision and (2) Adversarial Overlap Region Discriminator. The former utilizes the traditional stereo disparity estimation method to obtain reliable disparity information from the overlap region. Given the disparity estimates as supervision, we propose regularizing the network to fully utilize the geometric potential of binocular images and improve the overall detection accuracy accordingly. Further, the latter module minimizes the representational gap between non-overlap and overlapping regions. We demonstrate the effectiveness of the proposed method with the nuScenes large-scale multi-view 3D object detection data. Our experiments show that our proposed method outperforms current state-of-the-art models, i.e., DETR3D and BEVDet.
Method
Train / Test Overview
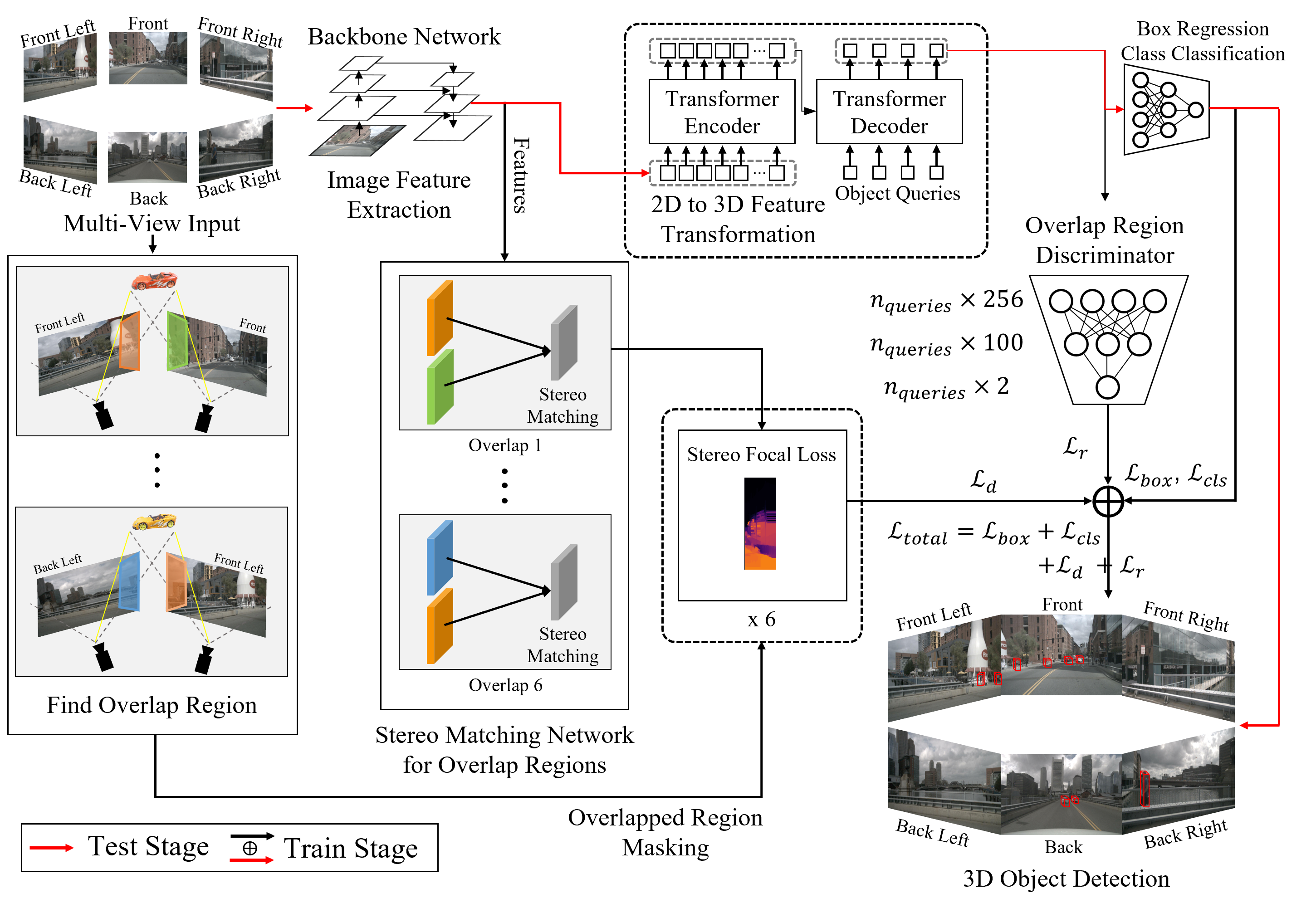
An overview of our proposed architecture. Built upon DETR3D, our model takes multi-view camera inputs and outputs a set of 3D bounding boxes for objects in the scene. Our model consists of two main modules: (1) Stereo Matching Network for Weak Depth Supervision, where our depth estimation head is trained to predict a dense depth map of the overlap region. The ground-truth depth map is obtained by a traditional stereo disparity estimation algorithm. (2) Adversarial Overlap Region Discriminator, which minimizes the gap between non-overlap regions vs. overlap regions, improving the overall detection performance.
Stereo Disparity Estimation
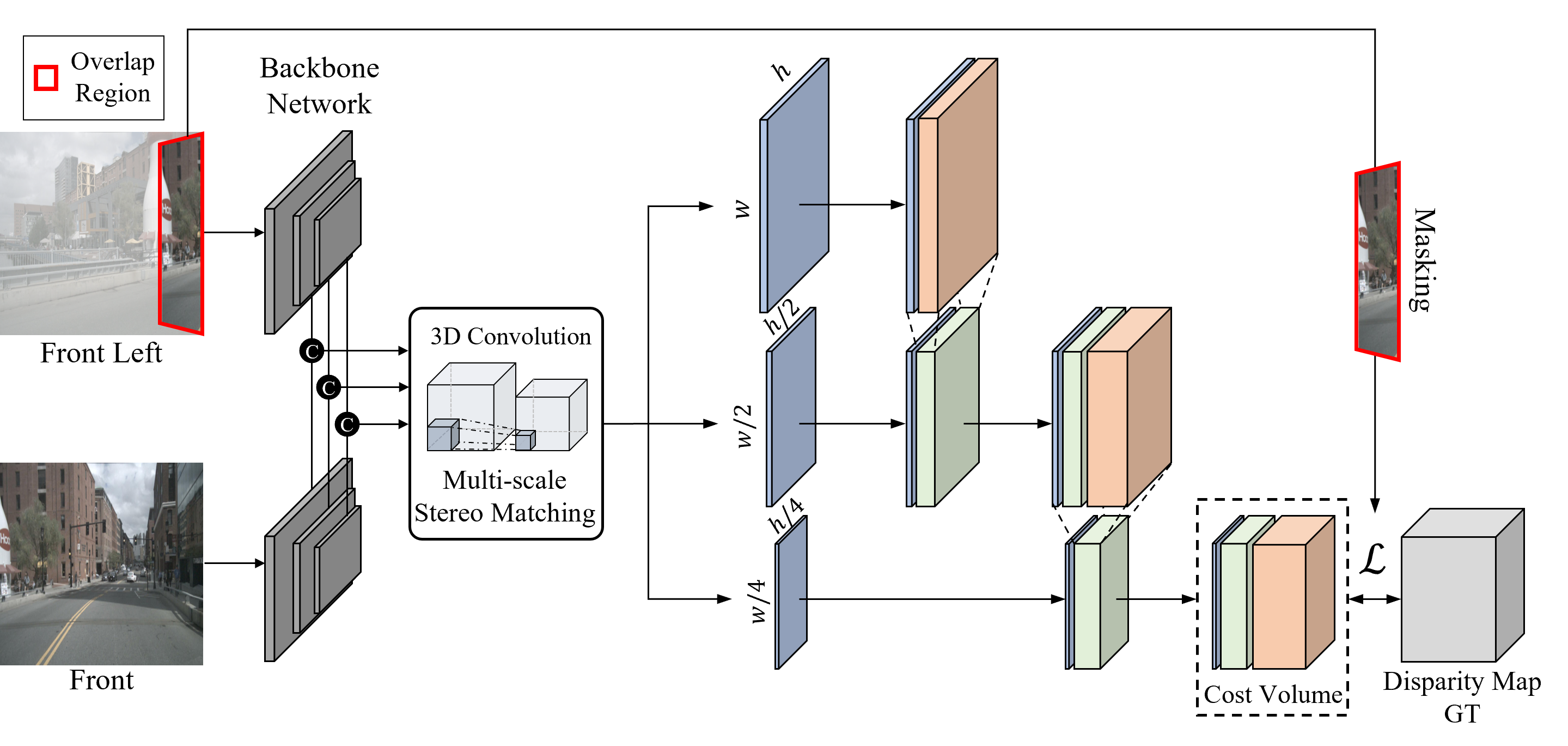
Following recent work by Liu, our Stereo Disparity Estimation head is co-trained to compute the disparity map from two overlapped images. As shown in figure above, Our stereo network extracts features of an image pair with a standard visual encoder. Our disparity estimation head outputs a cost volume through multi-scale stereo matching. To obtain the target disparity map, we use the output from the conventional stereo matching algorithm, which performs pixel-wise mutual information-based matching.
Qualitative Results

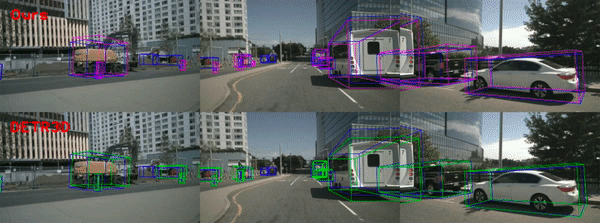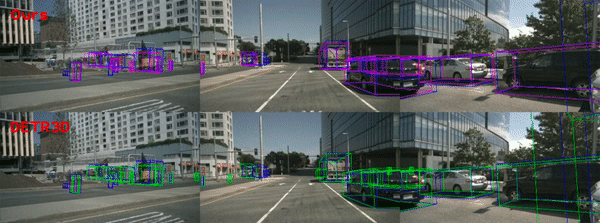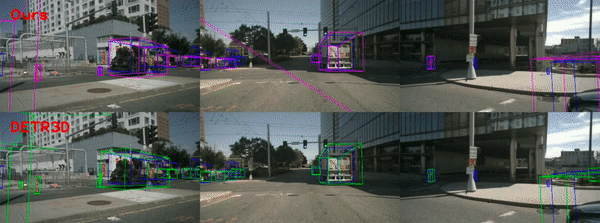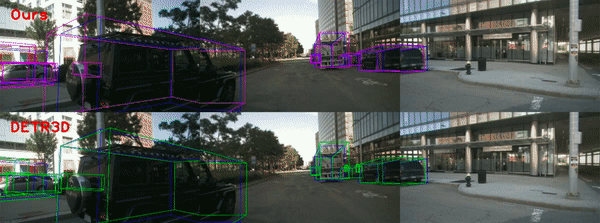

The blue, green, and magenta boxes denote ground truth, DETR3D prediction, and the prediction of our model, respectively.
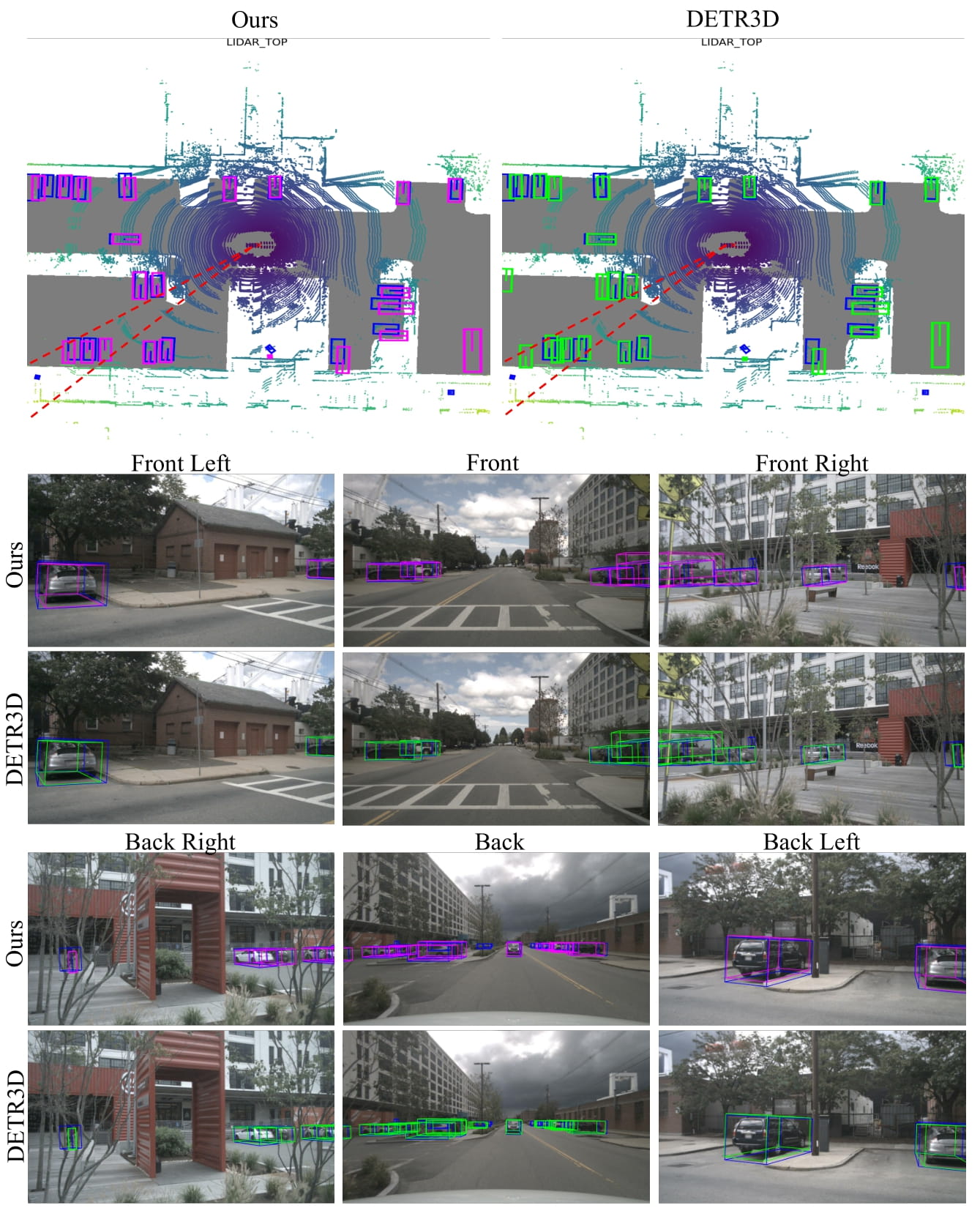

The blue, green, and magenta boxes denote ground truth, DETR3D prediction, and the prediction of our model, respectively.
The red dotted lines in the upper BEV images indicates the overlap region between the back right and back cameras of multi-view.