
Abstract
The recent success of the generative model shows that leveraging the multi-modal embedding space can manipulate an image using text information. However, manipulating an image with other sources rather than text, such as sound, is not easy due to the dynamic characteristics of the sources. Especially, sound can convey vivid emotions and dynamic expressions of the real world. Here, we propose a framework that directly encodes sound into the multi-modal (image-text) embedding space and manipulates an image from the space. Our audio encoder is trained to produce a latent representation from an audio input, which is forced to be aligned with image and text representations in the multi-modal embedding space. We use a direct latent optimization method based on aligned embeddings for sound-guided image manipulation. We also show that our method can mix text and audio modalities, which enrich the variety of the image modification. We verify the effectiveness of our sound-guided image manipulation quantitatively and qualitatively. We also show that our method can mix different modalities, i.e., text and audio, which enrich the variety of the image modification. The experiments on zero-shot audio classification and semantic-level image classification show that our proposed model outperforms other text and sound-guided state-of-the-art methods.
Method
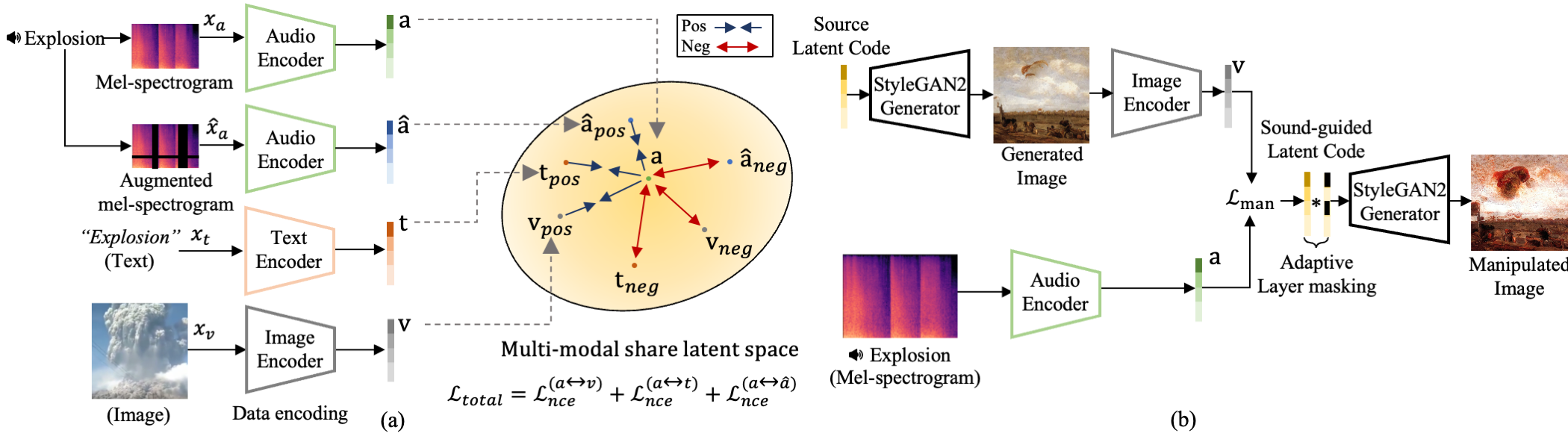
Our model consists of two main steps: (a) the CLIP-based Contrastive Latent Representation Learning step and (b) the Sound-Guided Image Manipulation step. In (a), we train a set of encoders with three different modalities (audio, text, and image) to produce the matched latent representations. The latent representations for a positive triplet pair (e.g., audio input: "Explosion", text: "explosion", and corresponding image) are mapped close together, while that of negative pair samples further away in the (CLIP-based) embedding space (left). In (b), we use a direct code optimization approach where a source latent code is modified in response to user-provided audio, producing a sound-guided image manipulation result (right).
Manipulation Results
Comparison of manipulation results between ours and the existing text-driven manipulation approach, StyleCLIP. Unlike the text-driven approach, ours can produce more diverse manipulation results in response to different intensities of raining, i.e. raining, raining with weak thunder, and raining with strong thunder.






The following manipulated results are obtained from the pretrained StyleGAN2 with the LSUN dataset.

The following manipulated results are obtained from the pretrained StyleGAN2 with the FFHQ dataset.

The LHQ dataset.
The AFHQ2 dataset.

→

🔊Wolf-howling

→

🔊Dog Barking

→

🔊Lion Roaring
Application.

🔊Fire Crackling
🔊Latin Music
BibTeX
If you use our code or data, please cite:
@InProceedings{Lee_2022_CVPR,
author = {Lee, Seung Hyun and Roh, Wonseok and Byeon, Wonmin and Yoon, Sang Ho and Kim, Chanyoung and Kim, Jinkyu and Kim, Sangpil},
title = {Sound-Guided Semantic Image Manipulation},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
month = {June},
year = {2022},
pages = {3377-3386}
}