Abstract
Image watermarking supports authenticity and provenance, yet many schemes are still easy to bypass with various distortions and powerful generative edits.
Deep learning-based watermarking has improved robustness to diffusion-based image editing, but a gap remains when a watermarked image is converted to video by image-to-video (I2V),
in which per-frame watermark detection weakens. I2V has quickly advanced from short, jittery clips to multi-second, temporally coherent scenes, and it now serves not only content creation
but also world-modeling and simulation workflows, making cross-modal watermark recovery crucial. We present WaTeRFlow, a framework tailored for robustness under I2V.
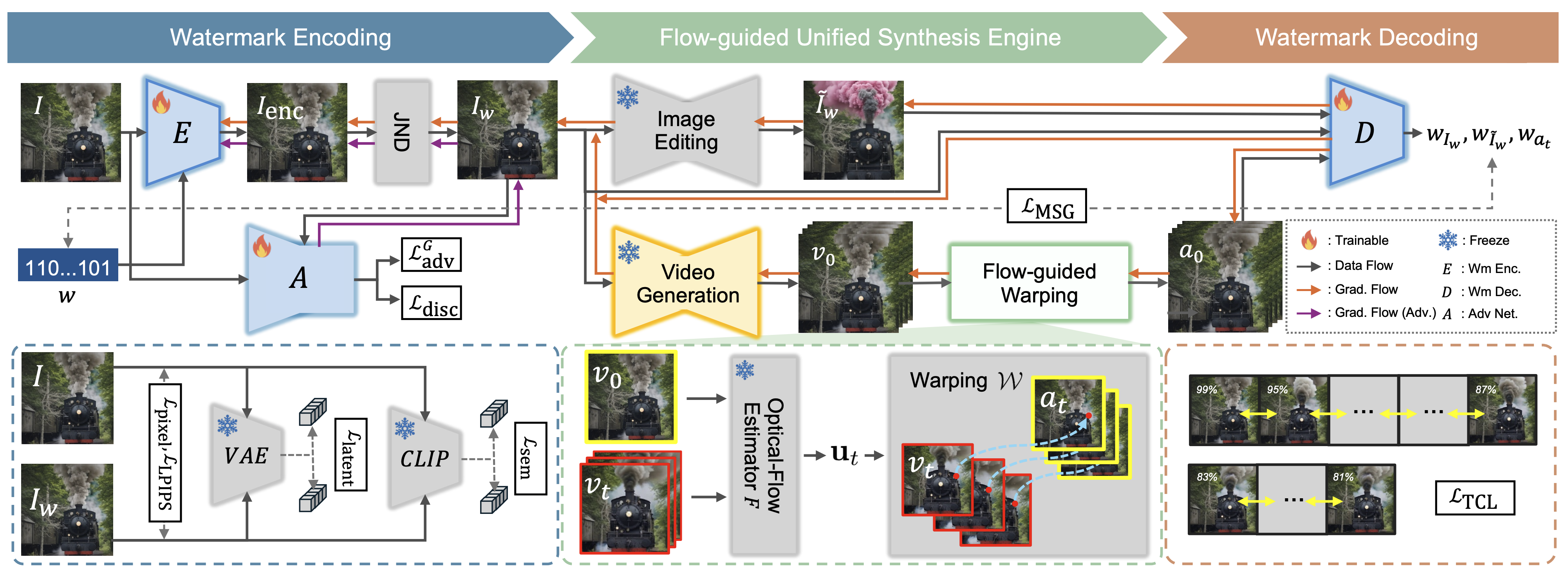
It consists of (i) FUSE (Flow-guided Unified Synthesis Engine), which exposes the encoder–decoder to realistic distortions via instruction-driven edits and a fast video diffusion proxy during training,
(ii) optical-flow warping with a Temporal Consistency Loss (TCL) that stabilizes per-frame predictions, and (iii) a semantic preservation loss that maintains the conditioning signal.
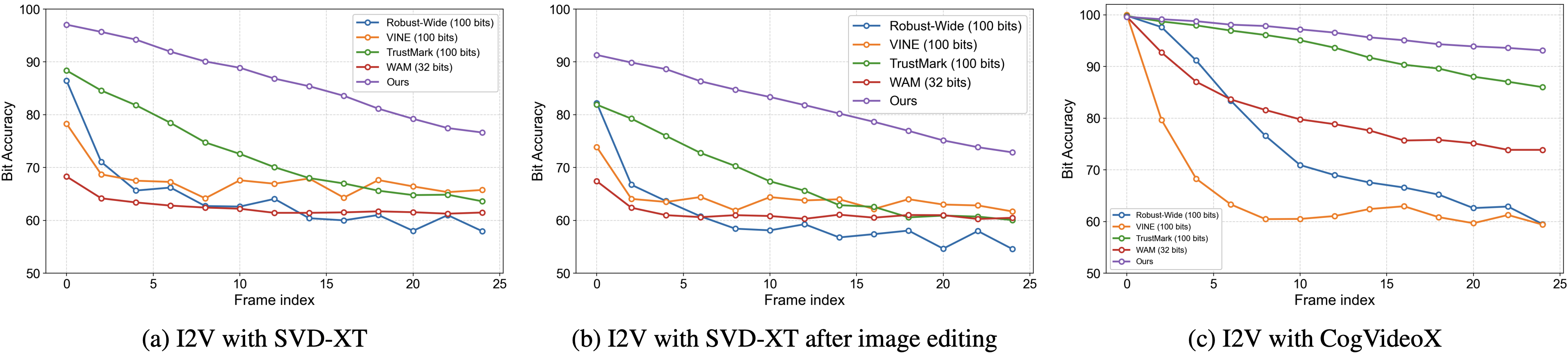
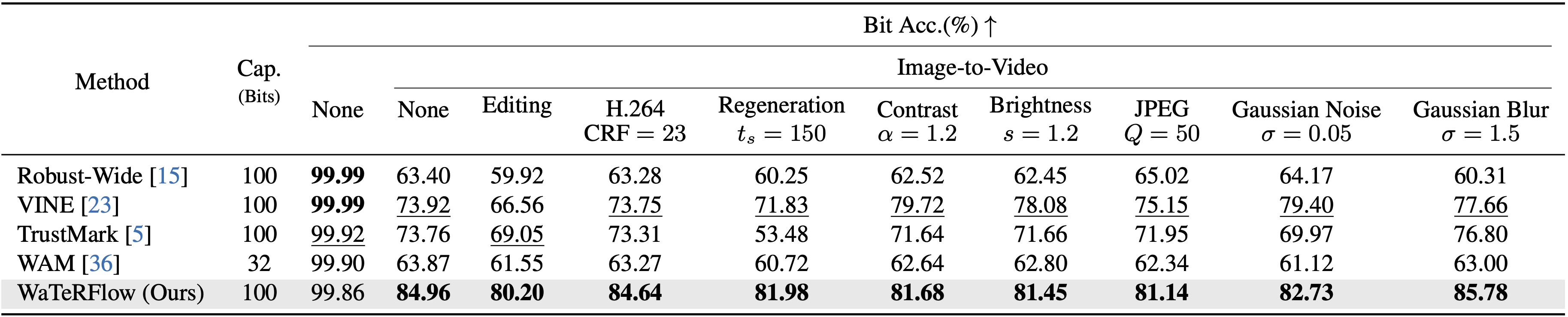
Experiments across representative I2V models show accurate watermark recovery from frames, with higher first-frame and per-frame bit accuracy and resilience when various distortions are applied before or after video generation.