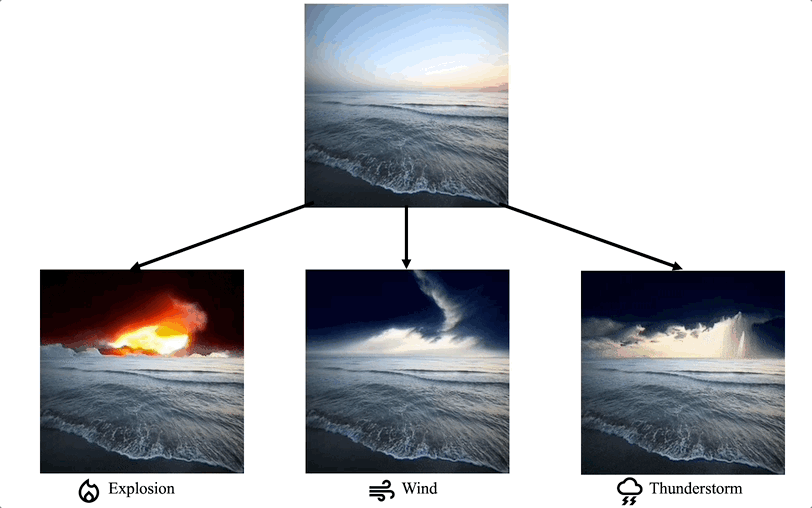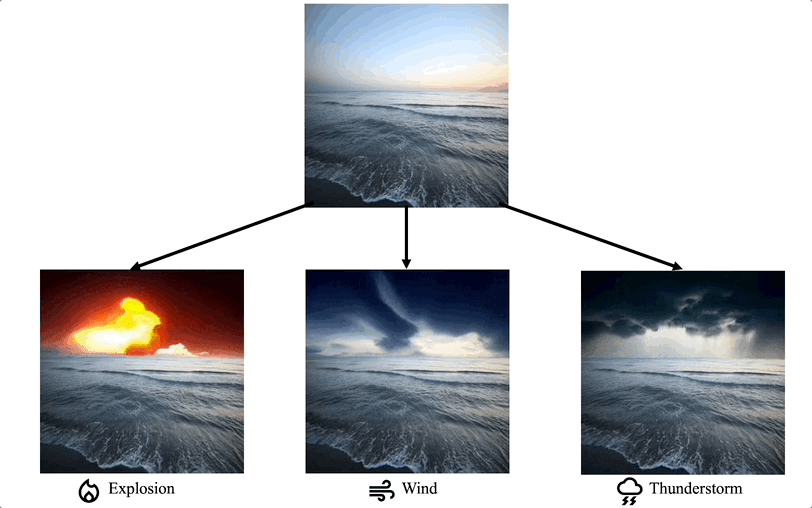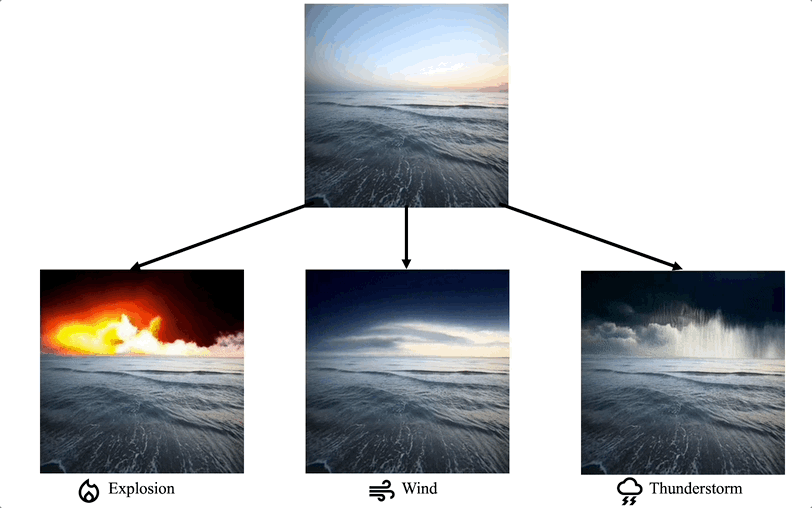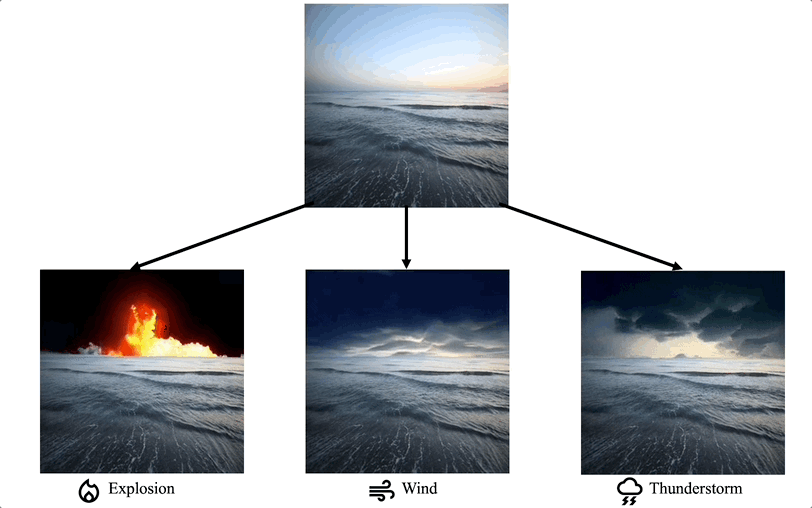

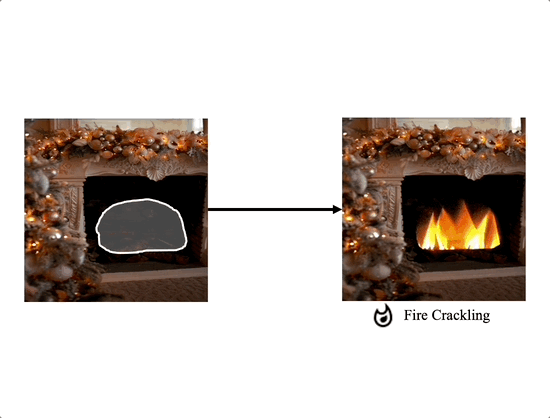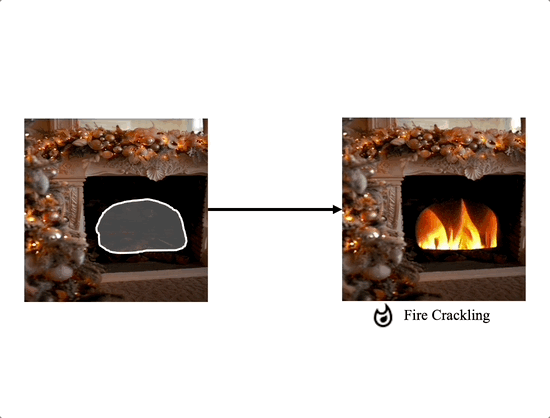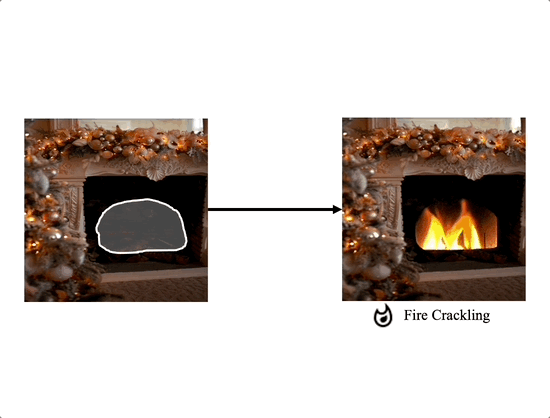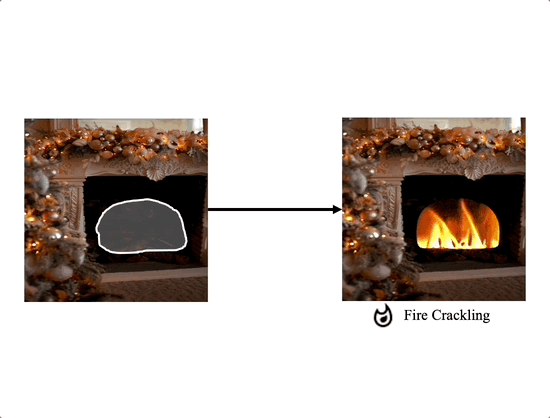
Comparison with the extension of image editing works

We propose a method for adding sound-guided visual effects to specific regions of videos with a zero-shot setting. Animating the appearance of the visual effect is challenging because each frame of the edited video should have visual changes while maintaining temporal consistency. Moreover, existing video editing solutions focus on temporal consistency across frames, ignoring the visual style variations over time, e.g., thunderstorm, wave, fire crackling. To overcome this limitation, we utilize temporal sound features for the dynamic style. Specifically, we guide denoising diffusion probabilistic models with an audio latent representation in the audio-visual latent space. To the best of our knowledge, our work is the first to explore sound-guided natural video editing from various sound sources with sound-specialized properties, such as intensity, timbre, and volume. Additionally, we design optical flow-based guidance to generate temporally consistent video frames, capturing the pixel-wise relationship between adjacent frames. Experimental results show that our method outperforms existing video editing techniques, producing more realistic visual effects that reflect the properties of sound.
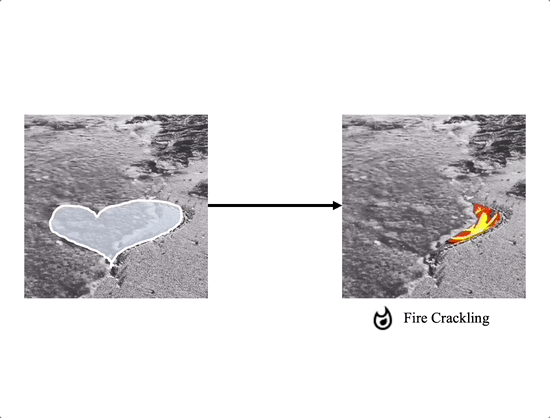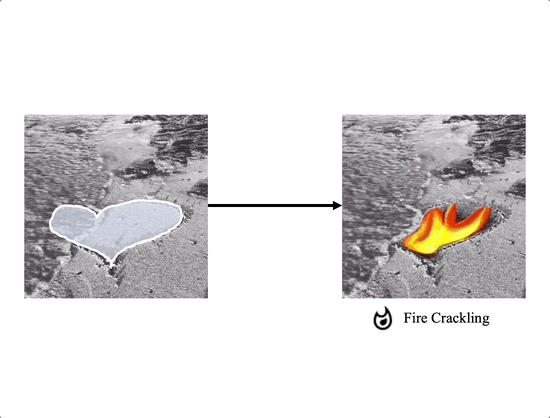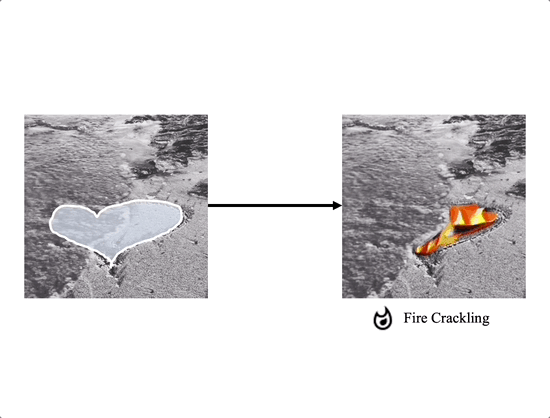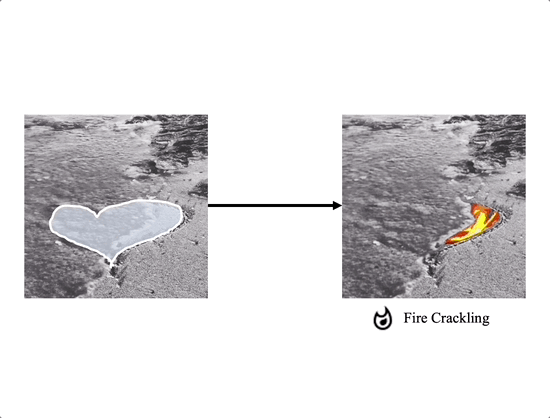


Soundini consists of two gradient-based guidance for diffusion: (a) Local Sound guidance and (b) Optical flow guidance. In (a), we match the appearance of the sampled frame with the sound in the mask region using the loss $\mathcal{L}_\text{SG}$ and $\mathcal{L}_\text{DSG}$. First, we minimize the cosine distance loss $\mathcal{L}_\text{SG}$ between the denoised frame and the sound segments in the audio-visual latent space. Additionally, the loss term $\mathcal{L}_\text{DSG}$ aligns the variation of frame latent representation and that of sound, capturing the transition of sound semantic and reaction. In (b), our optical flow guidance $\mathcal{L}_\text{flow}$ allows the sampled video to maintain temporal consistency by measuring the mean squared error between warped and sampled frames using optical flow. In particular, gradually increasing the influence on the loss $\mathcal{L}_\text{flow}$ helps to stably sample the temporally consistent video. Background reconstruction loss $\mathcal{L}_\text{back}$ allows the background to be close to the source video.

The frozen optical flow estimator produces bi-directional optical flows between the sampled frame $i$ and frame $i+1$. Then, we apply forward and backward warp to match each pixel and minimize the mean squared error between the adjacent and the corresponding warped frames.
@misc{lee2023soundini,
title={Soundini: Sound-Guided Diffusion for Natural Video Editing},
author={Seung Hyun Lee, Sieun Kim, Innfarn Yoo, Feng Yang, Donghyeon Cho, Youngseo Kim, Huiwen Chang, Jinkyu Kim, Sangpil Kim},
year={2023},
eprint={2304.06818},
archivePrefix={arXiv},
primaryClass={cs.CV}
}